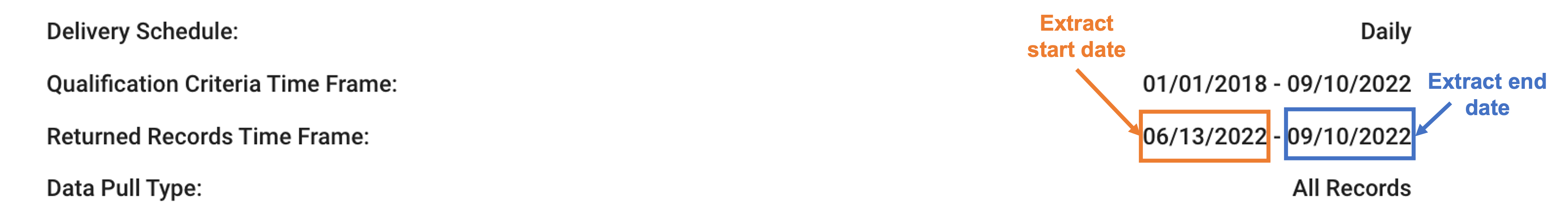On This Page
Accessing the Data
Veeva Compass offers a variety of different delivery options to help users download and pull data files in a way that best suits the user’s needs and technical capabilities. The following file formats and delivery locations are available for each subproduct:
| Subproduct | Available File Formats | Available Delivery Locations |
|---|---|---|
| Patient | CSV, Parquet, Excel | SFTP, Amazon S3, Microsoft Azure, Portal Download, Veeva Nitro, Veeva CRM |
| Pathway | CSV, Parquet, Excel | SFTP, Amazon S3, Microsoft Azure, Portal Download |
| Referrals | CSV, Excel | SFTP, Portal Download |
| Prescriber | CSV, Parquet, Excel | SFTP, Amazon S3, Microsoft Azure, Portal Download, Veeva Nitro, Veeva CRM |
| Zip | CSV, Parquet, Excel | SFTP, Amazon S3, Microsoft Azure, Portal Download, Veeva Nitro |
| National | CSV, Parquet, Excel | SFTP, Amazon S3, Microsoft Azure, Portal Download, Veeva Nitro |
| State | CSV, Parquet, Excel | SFTP, Amazon S3, Microsoft Azure, Portal Download, Veeva Nitro |
SFTP
Available for all Compass data pulls.
One delivery method offered by Veeva Compass is to a Veeva-hosted SFTP server. This allows users to easily access their data in a reliable, secure manner through the many SFTP clients available for free. The SFTP server also contains a predictable folder naming convention which helps aid users in automating loading processes.
Note The Veeva Compass Portal and other delivery destinations are tools for data delivery and data access to Veeva Compass data for use during a customer’s subscription to Veeva Compass. They are not intended for use as long-term data storage and are subject to Veeva’s retention policy for data delivery tools.
How to Access Compass SFTP
Credentials
To access Veeva’s SFTP server, a user must have an active portal account as this provides the username and password needed to log in.
- Host: sftp://transfer.veevacompass.com
- Username / Password: Your Veeva Compass Portal credentials
- Port: 22
Connecting for Local Access
In order to access the SFTP server, a user can use a FTP client installed such as FileZilla or Cyberduck to access the data. Once installed, use the portal credentials to log in to the server.
If the user is encountering issues with timeout when logging into the server, we recommend updating the connection timeout setting to 60 seconds. This can be found under the connection settings for the FTP client.

Once logged in, the user will be able to navigate the FTP server and view/download the files for completed jobs they have access to.
Remote Host Access
For automated ingestion we recommend connecting to SFTP via command line/python/java libraries.
We do not recommend building ingest pipelines using FTP clients such as Filezilla or Cyberduck.
Note If users are having issues accessing the Portal or SFTP Directory, the locations may need to be added to your company’s VPN allowable sites list.
Finding a Specific Compass Job
To locate data for a specific Job, first look up the Job information in the Portal, then go to SFTP to locate that Job’s information.
Key Job Information includes:
| Attribute | Description |
|---|---|
| Instance Name | Instance name is the company name |
| License ID | Up to 3-digit numeric identifier that indicates the unique License ID that was used for the job. There can be multiple License IDs under a single Instance Name. |
| Query ID | Up to 6-digit numeric identifier that indicates the unique query ID that was used for the job. There can be multiple Query IDs under a single License ID. |
| Query Name | Description or alias of the query that was used to produce the job. |
| Job ID | Up to 8-digit numeric identifier that indicates a unique job number given to the data request. There can be multiple Job IDs under a single Query ID. |
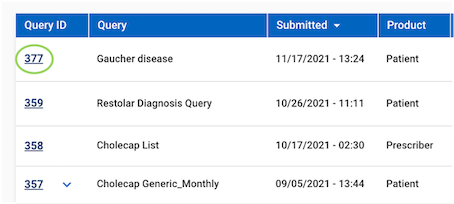
Locate Job Information in the Portal
Use the Job Receipt in the Portal to find directory information on the specific job.
The delivery location and directory can be found in the job receipt in the Job Manager tab.
- Click the Query ID for the Job you would like to locate
- A pop-up will indicate key details regarding the job. This will provide you with the specific SFTP directory path, which includes the Instance ID, License ID, Query ID, Query Name and Job ID.
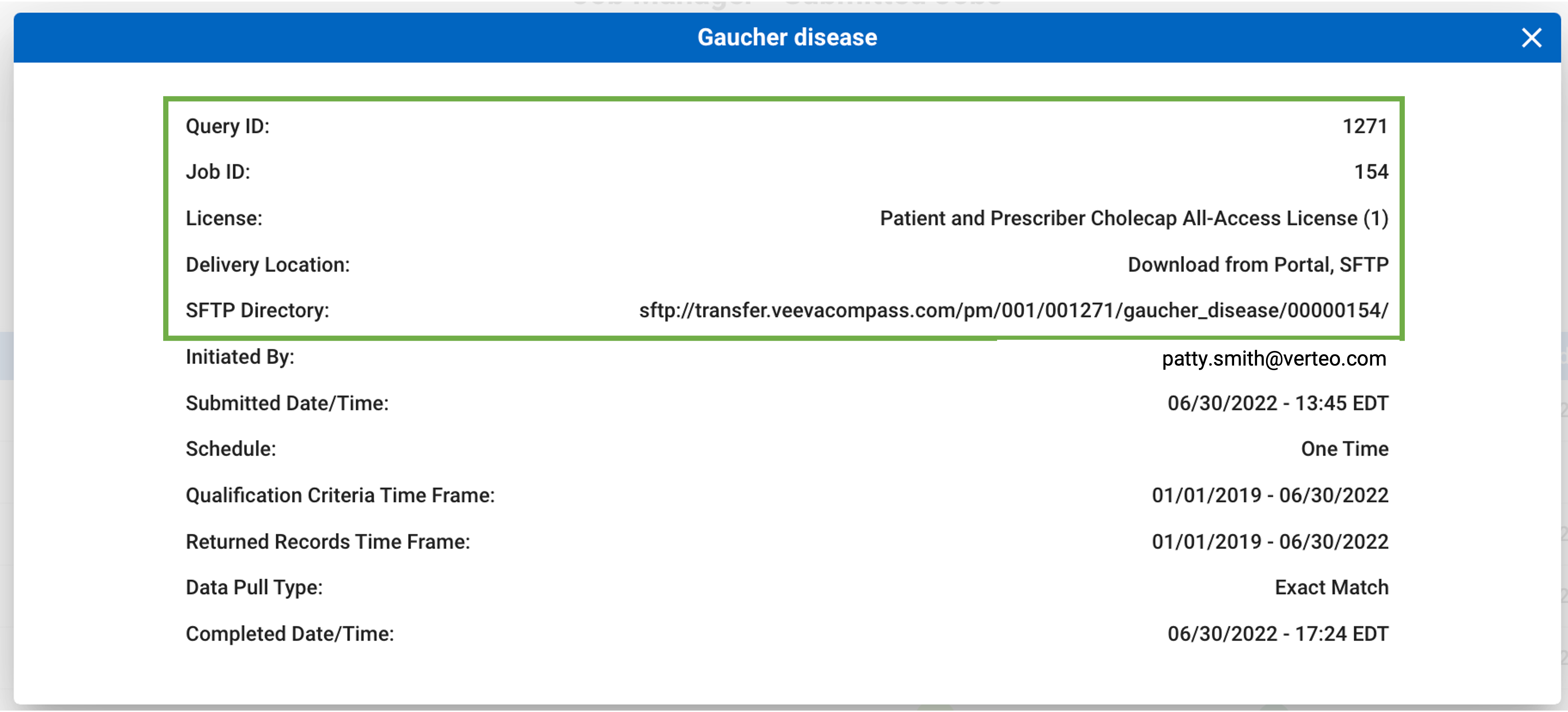
Locate Job Information in the SFTP Directory
SFTP folders will follow the standard naming convention: [Instance Name] / [License ID] / [Query ID] / [Query Name] / [Job ID]
For example, a path will look like: company_abc/002/000123/my_query/00000001
Locate the directory based on the information provided in the Job Receipt in the Portal.
Veeva CRM
Available for Patient and Prescriber data pulls.
Veeva CRM allows users to deliver Veeva Compass data directly to the field team, through powerful MyInsights content that is updated and easily accessible by field teams.
The CRM option is available for users with an active CRM MyInsights subscription. Note that CRM is only available for Patient daily data queries and Prescriber monthly data queries. Currently, one active daily Patient query and one active monthly Prescriber query can be sent to CRM MyInsights per customer. For more information on setting up the Compass CRM integration, refer to the CRM Help Site and reach out to your Compass Product Expert.
Veeva Nitro
Available for Patient, Prescriber, Zip, National, and State data pulls.
Veeva Nitro is a data science and analytics platform that seamlessly integrates with Veeva Compass. Nitro provides faster access to your data, so you have your data ready for querying, visualizing and reporting.
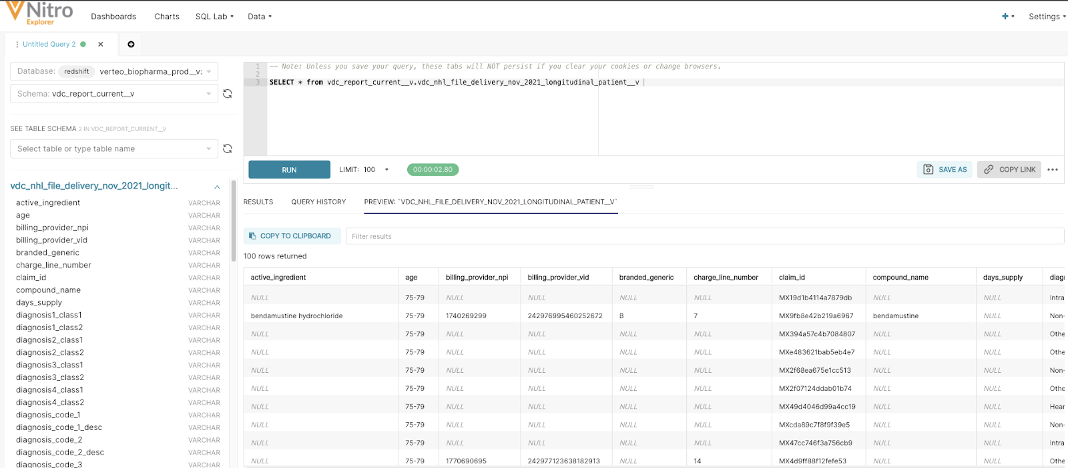
The Veeva Nitro option is available for users with an active Nitro subscription. The Nitro option will be able to be selected in the Delivery Options step for users with an active subscription, and greyed out if no subscription exists.
Amazon S3
Available for Patient, Pathway, Prescriber, Zip, National, and State data pulls.
Compass allows you to directly deliver your data files to an Amazon S3 bucket. The Amazon S3 option is only available for users with a pre-configured Amazon S3 bucket. Refer to Setting up an Amazon S3 Bucket for more information on S3 bucket setup.
Microsoft Azure
Available for Patient, Pathway, Prescriber, Zip, National, and State data pulls.
Compass allows you to deliver your data files to Microsoft Azure. The Azure option is only available for users with a pre-configured Azure container. Refer to Setting up a Microsoft Azure container for more information on Azure container setup.
Portal Download
Available for all Compass data pulls.
For Patient or Pathway Data pulls, in order to help business users more quickly and easily access data, an Excel file will be automatically created and made available in Portal for all one-time and monthly jobs with fewer than 800k records. When an Excel file is available for a delivery, the user will be notified via email upon job completion. This Excel file will be provided in addition to the CSV file in your choice of destination. Excel Delivery applies to both one-time pulls and monthly scheduled jobs. Note that this file will not be generated for daily or weekly jobs.
For Referrals, Prescriber, Zip, State, and National jobs, the Excel file will be available if the option was selected as a Delivery Option when submitting the job.
Once your job has completed processing, you can download the data file directly from the Portal by clicking Download Data from the Actions menu in the Job Manager. The data file will download directly to your computer and be available in your downloads folder.
Understanding the Files & Format
Compass data can be delivered in several different file formats and types: CSV, Parquet, and Excel.
CSV
Available for all Compass data pulls.
The CSV file format is delivered in a pipe-delimited file. Each job will include the data files, as well as supporting documents to help either A) provide information to assist with data ingest, or B) help users better understand the data.
The following files are provided:
- Data files
- Supporting Files for Data Ingest:
- Header
- Manifest
- Record Count
- Supporting Files for End Users:
- Job Summary
- Data Dictionary
To locate data for a specific Job, first look up the Job information in the Portal, then go to SFTP to locate that Job’s information.
Data Files (CSV)
Data files include the Compass data that was requested in the query (e.g. claims data, referrals data).
If the dataset file size is smaller than 5GB, the data will be delivered as a single file.
If the dataset file size is larger than 5GB, the data will be delivered as multiple files, unzipped. Files are automatically split and provided by Compass with a max size of 5 GB. This size limits the risk of file downloads failing from SFTP. Files are unzipped for SFTP and gzipped for Amazon S3. Headers (attribute name) are present in each file.
Below are the contents and file naming conventions for each subproduct:
| Compass Subproduct | Contents | File Naming Convention |
|---|---|---|
| Patient | Patient level prescription and medical claims | PA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].csv |
| Pathway | Record stage level prescription and medical claims | PW_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].csv |
| Referrals | Prescriber level referrals data | PA_REF_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].csv |
| Prescriber | Prescriber (HCP and HCO) level projected data | PR_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].csv |
| Zip | Zip level projected data | ZI_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].csv |
| National | National level projected data | NA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].csv |
| State | State level projected data | ST_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].csv |
Supporting Files for Data Ingest (CSV)
The following supporting files are included in each job to facilitate loading data directly into your data warehouse.
Header
This is a CSV file containing a list of all columns used for the data deliverable.
Below are the file naming conventions for each subproduct:
| Subproduct | File Naming Convention |
|---|---|
| Patient | PA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_header.csv |
| Pathway | PW_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_header.csv |
| Referrals | PA_REF_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_header.csv |
| Prescriber | PR_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_header.csv |
| Zip | ZI_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_header.csv |
| National | NA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_header.csv |
| State | ST_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_header.csv |
Manifest
This is a JSON file containing a list of parameters describing the file properties (delimiters, naming convention, format), as well as query and job information.
The manifest file consists of the following fields:
File Properties
- format = The format of the file, ie. CSV, Parquet
- separator = The field separator in the file
- quotechar = The character that will surround strings
- escapeChar = The character used to identify a special character in the field
- terminator = The end of line character
- nullstring = The value printed out if the field is null
- encoding = The character encoding of the file
- compression = The compression applied to the file
- manifestVersion = The version of the manifest file
- header = The header file name
- pattern = The file naming convention pattern for data sets created
- count = Number of data sets created (not record count)
Query Information
- id = The unique ID assigned to the Compass query created. This ID can also be found in Job Manager
- name = The query name
- schedule = The schedule of the query, ie ONE-TIME, DAILY, WEEKLY, MONTHLY
- jobType = Indicates whether the job has a full refresh, or if it is using the standard scheduled dates. Possible values are STANDARD, FULL_REFRESH
- extractTimeRange = The extract time range encompassed, ie FIXED_DATES, THREE_MONTHS, THIRTEEN_WEEKS, NINETY_DAYS
- extractStartDate = The start date of the exported data result
- extractEndDate = The end date of the exported data result
Job Information
- id = Up to 8-digit numeric identifier that indicates a unique job number given to the data request. There can be multiple Job IDs under a single Query ID
- product = The Compass product that the job was submitted for (e.g. PATIENT, PATHWAY, PRESCRIBER, NATIONAL)
- subProduct = The Compass sub-product that the job was submitted for (e.g. CLAIMS, REFERRALS, CLAIMS_LIFECYCLE, PRESCRIBER, ZIP, NATIONAL, STATE)
- licenseId = Up to 3-digit numeric identifier that indicates the unique License ID that was used for the job
- licenseName = The name of the license used for the job
- jobType = Indicates whether the job has an override on its submitted dates (e.g. STANDARD, FULL_REFRESH)
- jobRerun = Indicates whether the job was run off schedule (e.g. true, false)
- schemaVersion = The version of the schema (e.g. patient_schema_v2)
Below are the file naming conventions for each subproduct:
| Subproduct | File Naming Convention |
|---|---|
| Patient | PA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_manifest.json |
| Pathway | PW_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_manifest.json |
| Referrals | PA_REF_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_manifest.json |
| Prescriber | PR_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_manifest.json |
| Zip | ZI_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_manifest.json |
| National | NA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_manifest.json |
| State | ST_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_manifest.json |
Record Count
This is a CSV file providing the record count per data file.
Below are the file naming conventions for each subproduct:
| Subproduct | File Naming Convention |
|---|---|
| Patient | PA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_RecordCounts.csv |
| Pathway | PW_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_RecordCounts.csv |
| Referrals | PA_REF_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_RecordCounts.csv |
| Prescriber | PR_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_RecordCounts.csv |
| Zip | ZI_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_RecordCounts.csv |
| National | NA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_RecordCounts.csv |
| State | ST_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_RecordCounts.csv |
Note Data is split into individual files based on 5GB size. Use Counts in the Manifest file to determine the number of files.
Parquet
Available for Patient, Pathway, Prescriber, Zip, National, and State data pulls.
The Parquet file format is delivered as compressed .snappy.parquet files. Each job will include the data files, as well as supporting documents to help either A) provide information to assist with data ingest, or B) help users better understand the data.
The following files are provided:
- Data files
- Supporting Files for Data Ingest:
- Manifest
- Record Count
- Supporting Files for End Users:
- Data Dictionary
- Job Summary
To locate data for a specific Job, first look up the Job information in the Portal, then go to SFTP to locate that Job’s information.
Data Files (Parquet)
Data files include the Compass data that was requested in the query (e.g. claims data, referrals data).
If the dataset file size is smaller than 500MB, the data will be delivered as a single file.
If the dataset file size is larger than 500MB, it will be delivered as multiple files, unzipped. Files are compressed for SFTP and Amazon S3 with snappy. Headers (attribute name) will be present in each file.
Below are the contents and file naming conventions for each subproduct:
| Subproduct | Contents | File Naming Convention |
|---|---|---|
| Patient | Patient level prescription and medical claims | PA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].snappy.parquet |
| Pathway | Record stage level prescription and medical claims | PW_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].snappy.parquet |
| Prescriber | Prescriber (HCP and HCO) level projected data | PR_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].snappy.parquet |
| Zip | Zip level projected data | ZI_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].snappy.parquet |
| National | National level projected data | NA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].snappy.parquet |
| State | State level projected data | ST_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].snappy.parquet |
Supporting Files for Data Ingest (Parquet)
The following supporting files are included in each job to facilitate loading data directly into your data warehouse.
Manifest
This is a JSON file containing a list of parameters describing the file properties (delimiters, naming convention, format), as well as query and job information.
The manifest file consists of the following fields:
File Properties
- format = The format of the file, ie. CSV, Parquet
- separator = The field separator in the file
- quotechar = The character that will surround strings
- escapeChar = The character used to identify a special character in the field
- terminator = The end of line character
- nullstring = The value printed out if the field is null
- encoding = The character encoding of the file
- compression = The compression applied to the file
- manifestVersion = The version of the manifest file
- header = The header file name
- pattern = The file naming convention pattern for data sets created
- count = Number of data sets created (not record count)
Query Information
- id = The unique ID assigned to the Compass query created. This ID can also be found in Job Manager
- name = The query name
- schedule = The schedule of the query, ie ONE-TIME, DAILY, WEEKLY, MONTHLY
- jobType = Indicates whether the job has a full refresh, or if it is using the standard scheduled dates. Possible values are STANDARD, FULL_REFRESH
- extractTimeRange = The extract time range encompassed, ie FIXED_DATES, THREE_MONTHS, THIRTEEN_WEEKS, NINETY_DAYS
- extractStartDate = The start date of the exported data result
- extractEndDate = The end date of the exported data result
Job Information
- id = Up to 8-digit numeric identifier that indicates a unique job number given to the data request. There can be multiple Job IDs under a single Query ID
- product = The Compass product that the job was submitted for (e.g. PATIENT, PATHWAY, PRESCRIBER, NATIONAL)
- subProduct = The Compass sub-product that the job was submitted for (e.g. CLAIMS, REFERRALS, CLAIMS_LIFECYCLE, PRESCRIBER, ZIP, NATIONAL, STATE)
- licenseId = Up to 3-digit numeric identifier that indicates the unique License ID that was used for the job
- licenseName = The name of the license used for the job
- jobType = Indicates whether the job has an override on its submitted dates (e.g. STANDARD, FULL_REFRESH)
- jobRerun = Indicates whether the job was run off schedule (e.g. true, false)
- schemaVersion = The version of the schema (e.g. patient_schema_v2)fo
Below are the file naming conventions for each subproduct:
| Subproduct | File Naming Convention |
|---|---|
| Patient | PA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_manifest.json |
| Pathway | PW_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_manifest.json |
| Prescriber | PR_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_manifest.json |
| Zip | ZI_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_manifest.json |
| National | NA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_manifest.json |
| State | ST_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_manifest.json |
Record Count
This is a CSV file providing the record count per data file.
Below are the file naming conventions for each subproduct:
| Subproduct | File Naming Convention |
|---|---|
| Patient | PA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_RecordCounts.csv |
| Pathway | PW_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_RecordCounts.csv |
| Prescriber | PR_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_RecordCounts.csv |
| Zip | ZI_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_RecordCounts.csv |
| National | NA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_RecordCounts.csv |
| State | ST_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_RecordCounts.csv |
Note Data is split into individual files based on 500MB size. Use Counts in the Manifest file to determine the number of files.
Supporting Files for End Users
The following supporting files are included in each job to support end users with using and interpreting the data.
Job Summary
This is a summary outlining job information for the data deliverable. Contents depend on the type of dataset:
Patient and Pathway Data
- Summary outlining high-level statistics about the data file such as annual total records, distinct patients and HCPs for each year.
- Qualification Criteria and Returned Records Criteria: the list of diagnosis codes, procedure codes, and NDCs that are used to qualify patients or returned records for this data set.
- Time frame definition: Time frame for the qualification and returned transactions, data pull type
Referrals
- Summary includes a market definition. I.e. the list of diagnosis codes and/or brands and NDCs that are used to qualify patients for inclusion in the dataset as well as the selected attributes and time frame.
Prescriber, Zip, State, and National Data
- Summary includes the selected products and time frame, as well as the available metrics in the file.
Below are the file naming conventions for each subproduct:
| Subproduct | File Naming Convention |
|---|---|
| Patient | PA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_JobSummary.xlsx |
| Pathway | PW_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_JobSummary.xlsx |
| Referrals | PA_REF_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_JobSummary.xlsx |
| Prescriber | PR_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_JobSummary.xlsx |
| Zip | ZI_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_JobSummary.xlsx |
| State | ST_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_JobSummary.xlsx |
| National | NA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_JobSummary.xlsx |
Data Dictionary
This is an Excel file that provides the most recent list of attributes included in the Compass data deliverables, along with supporting descriptions, examples, and data types for the attributes.
Excel
Available for all Compass data pulls.
For Patient or Pathway data pulls, in order to help business users more quickly and easily access data, an Excel file will be automatically created and made available in Portal for all one-time and monthly jobs with fewer than 800k records. When an Excel file is available for a delivery, the user will be notified via email upon job completion. This Excel file will be provided in addition to the CSV file in your choice of destination. Excel Delivery applies to both one-time pulls and monthly scheduled jobs. Note that this file will not be generated for daily or weekly jobs.
For Referrals, Prescriber, Zip, State, and National jobs, the Excel file will be available if the option was selected as a Delivery Option when submitting the job. Note that each tab within the Prescriber, Zip, State and National Excel files will be truncated at 600K rows.
Below are the file naming conventions for each subproduct:
| Subproduct | File Naming Convention |
|---|---|
| Patient | PA_[Query Name]_[Job ID]_YYYYMMDD.xlsx |
| Pathway | PW_[Query Name]_[Job ID]_YYYYMMDD.xlsx |
| Referrals | PA_REF_[Query Name]_[Job ID]_YYYYMMDD.xlsx |
| Prescriber | PR_[Query Name]_[Job ID]_YYYYMMDD.xlsx |
| Zip | ZI_[Query Name]_[Job ID]_YYYYMMDD.xlsx |
| National | NA_[Query Name]_[Job ID]_YYYYMMDD.xlsx |
| State | ST_[Query Name]_[Job ID]_YYYYMMDD.xlsx |
Tips for Setting up Data Ingest
Query Types
Users can run queries in the Portal in 2 ways -
- One Time Pulls - an individual ad hoc data pull. Generally used for one-time analytics.
- Scheduled Jobs - Recurring jobs. Generally used to feed into a data warehouse where automated analytics, reporting and dashboards are built. Jobs can be delivered on a monthly, weekly, or daily basis.
Note Use the Query ID to locate a specific scheduled job when setting up a data pipeline that will feed specific automatically updating reports or dashboards.
File Naming
Data files will follow the standard naming convention:
| Compass Subproduct | Contents | File Naming Convention |
|---|---|---|
| Patient | Patient level prescription and medical claims | PA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].csv |
| Pathway | Record stage level prescription and medical claims | PW_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].csv |
| Referrals | Prescriber level referrals data | PA_REF_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].csv |
| Prescriber | Prescriber (HCP and HCO) level projected data | PR_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].csv |
| Zip | Zip level projected data | ZI_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].csv |
| National | National level projected data | NA_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].csv |
| State | State level projected data | ST_YYYYMMDDhhmmss_[Instance ID]_[License ID]_[Query ID]_[Job ID]_[Data File Number].csv |
The above file naming convention is fixed length and would be padded with 0’s to fill to the required length. For example, a Job ID of 123 would be padded to 00000123.
For example, a data file will look like: PA_20210409101525_12345_021_000123_00123456_000001.csv, or PA_20210409101525_12345_021_000123_00123456_000002.csv
| Attribute | Description |
|---|---|
| Compass Subproduct | Indicates whether the file is a Patient (PA), Pathway (PW), Referrals (PA_REF), Prescriber (PR), Zip (ZI), State (ST), or National (NA) data deliverable. |
| YYYYMMDDhhmmss | Timestamp of the file. |
| Instance Name | Instance name is the company name |
| License ID | Up to 3-digit numeric identifier that indicates the unique License ID that was used for the job. |
| Query ID | Up to 6-digit numeric identifier that indicates the unique query ID that was used for the job. There can be multiple Query IDs under a single License ID. |
| Query Name | Description or alias of the query that was used to produce the job. |
| Job ID | Up to 8-digit numeric identifier that indicates a unique job number given to the data request. There can be multiple Job IDs under a single Query ID. |
| Data File Number (for data files) | Up to 6-digit numeric counter, used for data files - reset with each job. Will start at 000001 and increment for each individual file. |
Compass API
The Veeva Compass Public REST API allows users to retrieve real-time job and query information, such as job status and delivery location information, to support automated data ingest. For more information on accessing and using the API, refer to the Compass API Help Site.
Daily Data Ingest
Ingesting Daily Data into your Data Warehouse
Once your daily job is set-up in the Portal, the initial delivery will contain data from the dates selected by the user (this can be a full extract of data).
- Access your Patient files from your Compass SFTP or AWS S3 bucket. See Accessing the Data for information on accessing your Compass SFTP and the Patient files delivered.
- Load your Patient delivery files into your data warehouse.
Subsequent daily data deliverables will be incremental 90 days of data. To load subsequent daily data files:
- Access the latest daily data files from your Compass SFTP or AWS S3 bucket
- Find your daily data’s Extract Start Date and Extract End Date. See below on ways to find this information.
- Delete or drop the transactions between the daily job’s Extract Start Date and Extract End Date in the schema that the initial daily data was loaded to. For example, if the Extract Start Date is June 4, 2022 and Extract End Date is September 1, 2022, delete or drop the transactions that are between June 4, 2022 and September 1, 2022.
- Insert the new daily data files into the same schema as the initial daily data delivery.
How to Find Extract Start and End Date
Daily data Job Information can be found in the Manifest File, by making a Compass API request or through Portal’s Job Manager. We recommend using Compass API or the Manifest File to locate the daily data extract start and end date.
Manifest File
The manifest file is a JSON file containing a list of parameters describing the file format (delimiters, naming, convention, format, job information). The following query parameters listed in the manifest file will help your ingestion of daily data.
| Query Parameter | Description |
|---|---|
| id |
The unique ID assigned to the Compass query created. This ID can also be found in Job Manager |
| name |
The name of the query |
| schedule |
The schedule of the query, ie ONE-TIME, DAILY, WEEKLY, MONTHLY |
| jobType |
Indicates whether the job has a full refresh, or if it is using the standard scheduled dates. Possible values are STANDARD, FULL_REFRESH |
| extractTimeRange |
The extract time range encompassed, ie FIXED_DATES, THREE_MONTHS, THIRTEEN_WEEKS, NINETY_DAYS |
| extractStartDate |
The start date of the exported data result |
| extractEndDate |
The end date of the exported data result |
| Job ID |
Up to 8-digit numeric identifier that indicates a unique job number given to the data request. There can be multiple Job IDs under a single Query ID |
In the manifest file, the file parameters provide information surrounding the data file to help with the configuration when loading to your data warehouse.
| File Parameter | Description |
|---|---|
| format |
The format of the file, ie. CSV, PARQUET |
| separator |
The field separator in the file, ie '|' for CSV |
| quotechar |
The character that will surround strings |
| escapechar |
The character used to identify a special character in the field |
| terminator |
The end of line character |
| nullstring |
The value printed out if the field is null |
| encoding |
The character encoding of the file |
| compression |
The compression applied to the file |
Sample Daily Data Manifest
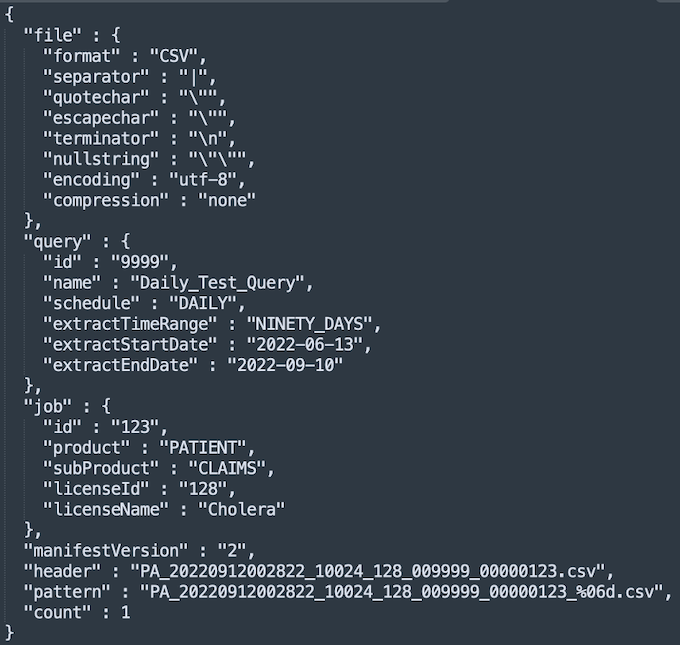
API
Compass API can also be leveraged to extract the query information. API provides the same information as the manifest file. For more information on using the API, see the Compass API Help Site.
| API Parameter | Description |
|---|---|
| queryDetails |
Contains information about the query including the query ID, name, Compass product and subproduct. |
| schedule |
The schedule of the query, ie ONE-TIME, DAILY, WEEKLY, MONTHLY |
| jobType |
Indicates whether the job has a full refresh, or if it is using the standard scheduled dates. Possible values are STANDARD, FULL_REFRESH |
| extractTimeRange |
The extract time range encompassed, ie FIXED_DATES, THREE_MONTHS, THIRTEEN_WEEKS, NINETY_DAYS |
| extractStartDate |
The start date of the exported data result |
| extractEndDate |
The end date of the exported data result |
Sample Daily Data API
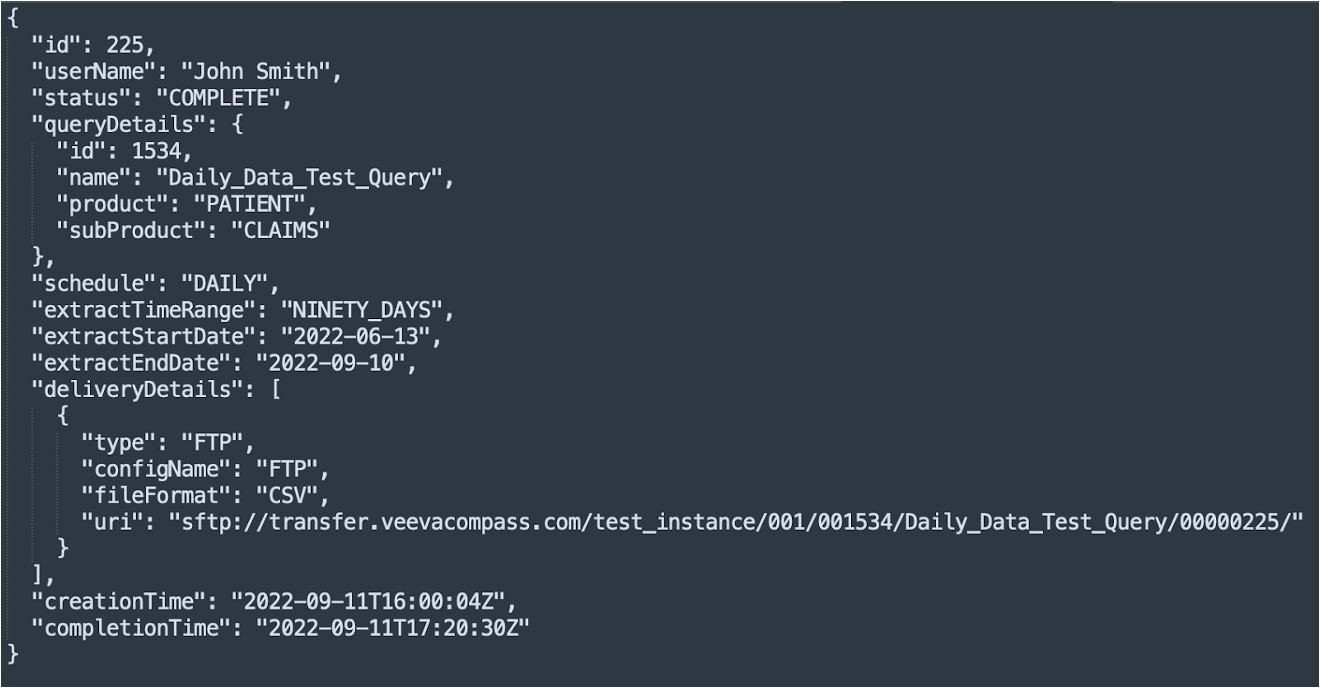
Job Manager
To find job information pertaining to a daily job, navigate to the Job Manager in your Compass Portal and expand the query ID, then click on the job ID to open the Job Receipt. The Extract start date and Extract end date are the start and end date of the Returned Records Time Frame displayed in the Job Receipt, respectively.
Note that for scheduled jobs, only the most recent 7 jobs are shown in Job Manager. Older scheduled job information can be retrieved via the Compass API.